Introduction
Machine learning is a forever growing topic. Applications are overwhelmingly abundant. In this post I’ll talk about the learning process itself. In particular, about Information Theoretic Learning (ITL in short).
To explain what this is, let me explain what learning means and what is the conventional way to do it. Basically, when someone refers to “machine learning” we need to understand what “machine” and “learning” are. To illustrate that, I’ll focus on a simple example that can be extended to more complex cases.
Lets consider a simple regression problem. In this problem, we have several pairs of measurements  and
and  (
( ) coming from some experiment or observed relation. The idea is that
) coming from some experiment or observed relation. The idea is that  depends on
depends on  following some rule (also called model). In this case, we will consider the super simple model given by
following some rule (also called model). In this case, we will consider the super simple model given by
![\[ y = a\,x+b \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-e2242d6f3c0a81aa2f96ba278b39e34b_l3.png "Rendered by QuickLaTeX.com")
The goal is to find the values of  and
and  that agrees with the measurements and that we have. We call this process “Fitting the model”. In general, we have a more complex model represented as
that agrees with the measurements and that we have. We call this process “Fitting the model”. In general, we have a more complex model represented as  , where
, where  is some function parametrized by
is some function parametrized by  . In the case of our simple model,
. In the case of our simple model, ![\mathbf{w} = [a, b]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-a09ba9d9395d80fd45411d3de409147e_l3.png "Rendered by QuickLaTeX.com") and
and  is the relation showed above. The following figure shows some plots related to this particular regression.
is the relation showed above. The following figure shows some plots related to this particular regression.
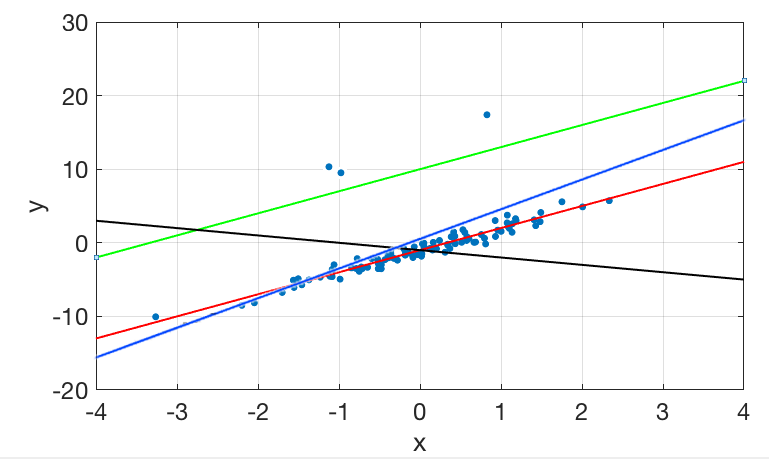
Figure 1: Plot of the measurements (blue dots) and some models (red, green, black and blue lines corresponding to values of and of  ,
,  for the red line, ,
for the red line, ,  for the green,
for the green,  , for the black and
, for the black and  and
and  for the blue)
for the blue)
In the figure, each line correspond to a certain pair of values of and . Each one is the result of a regression. Clearly, the “red model” is the best model of them all. That means that, the values of and are the values that most probably originated the measurements (apart of some random noise).
How to find those correct values of and ? If the measurements were perfect, all the (, ) pairs would fall exactly in the model line and we would only need two measurements to find and (why?). Since we have this noisy measurements, we need an algorithm to find the correct values of and .
That’s it. Going back to machine learning, the machine is the model and learn is the process of finding and . Simple as that. The concept of machine learning is extremely simple. What makes it an universe of theory and complexity are the different “machines” and “learning algorithms” that exists.
Going back to Information Theoretic Learning, ITL it is a “class” of algorithms that can be used to find the parameters of a model (in another words, to make a machine learn). Before diving into it, let me talk a bit about the conventional way that those algorithms work.
MSE
Out problem is to find a good model. What would be a suitable way to measure how good a model is? The first thing that people did (Gauss, I believe) was to compute the difference between the values of the measurement and what the model predicts based on its respective ( ). Hence, for each point, we have an error
). Hence, for each point, we have an error  . The following figure shows this concept.
. The following figure shows this concept.
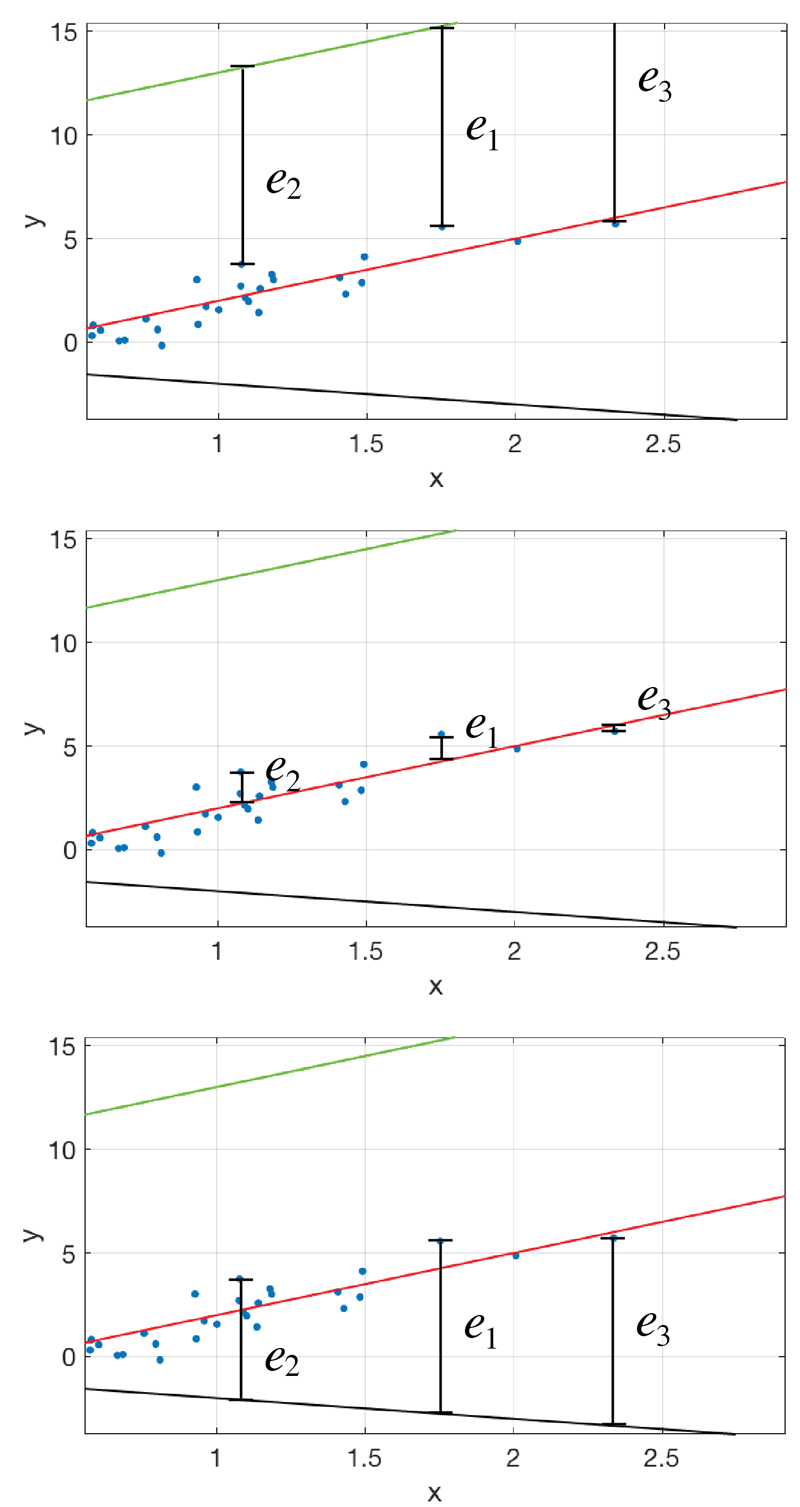
Figure 2: Error between model and data for the first 3 points and some models of figure 1. In reality, we consider the distance from the model to all points, not just the 3 first.
Now, depending on what you compute with those errors you have a different algorithm or class of algorithms. This computation that measures how good the model is called “cost function” (called here,  ). By far, the oldest and simples thing you can do is to simple sum all the squares of the errors as follows (why square?)
). By far, the oldest and simples thing you can do is to simple sum all the squares of the errors as follows (why square?)
![\[ J({\bf{w}}) = \sum\limits_{i = 1}^N {e_i^2} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-7b062265828a2109944d1de155097406_l3.png "Rendered by QuickLaTeX.com")
Notice that depend on . In the figure 2 above, each regression have its own and which, in essence, is one specific . Now, what you want to do is to “optimize” with respect to . In this case, optimize means pick the that produces the minimum . This was what people did (and still do) and is the famous “Mean Square Error” criteria (MSE).
Hence, MSE is a “class” of algorithms. Depending on how you minimize , you have a specific algorithm. Those algorithms can differ in several aspects like be interactive, analytic, recursive, etc, etc, etc. In this post we are not going to talk about this class of algorithms, we will talk about another class, the “entropy” based algorithms.
Entropy
Before explain how entropy based algorithms works, let me talk about why we would want to use entropy. I’ll assume that you know a bit of probability (as I was assuming, up to now, that you know calculus). Also, I’ll try to talk about some specifics aspects of the use of entropy (like outlier rejection). Please keep in mind that there is much more to it.
First, lets refer back to the example in figure 1. For each data point we have an error  associated with a specific regression. Since the data has a random part (the noise) the error is itself a random variable. So, for the example of figure 1, we would have four random variables, one for each model (given the same data). We see that each one have different statistical characteristics. For example, for the green model, we would have large values as being more probable and a very low probability of having small values. as for the black model, we would have a larger “spread” since low errors occur with a certain frequency (when the data is close to the model) but larger values are also present. So, if we have access to the different distributions for each model, we would see something like this
associated with a specific regression. Since the data has a random part (the noise) the error is itself a random variable. So, for the example of figure 1, we would have four random variables, one for each model (given the same data). We see that each one have different statistical characteristics. For example, for the green model, we would have large values as being more probable and a very low probability of having small values. as for the black model, we would have a larger “spread” since low errors occur with a certain frequency (when the data is close to the model) but larger values are also present. So, if we have access to the different distributions for each model, we would see something like this
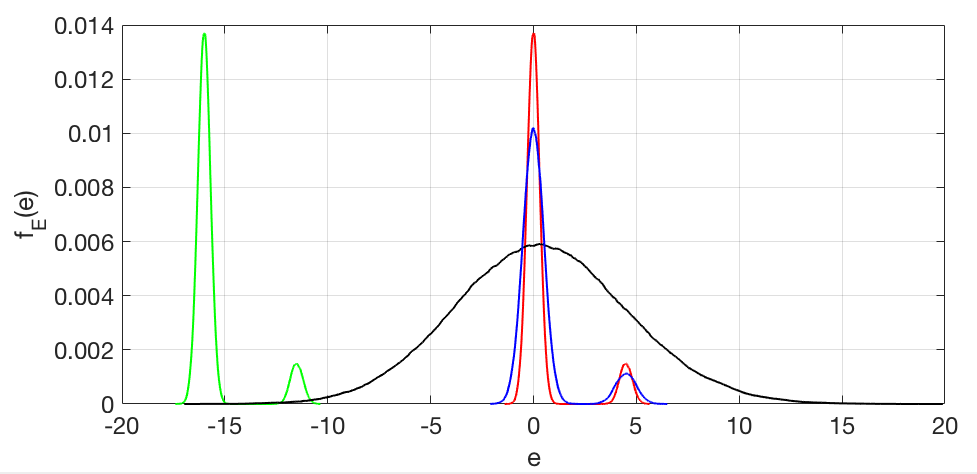
Figure 3: Probability distributions of the error for each data and models showed in figure 1.
Now, the sense of “what is best” changes a little… Looking to those plots on figure 3 and 1, what is the one that represents the best model? In the MSE case, the answer is clear: The best model is the one with less mean error squared. However, it turns out that, for those plots, the one with the least mean error squared error is the one with last second order statistics (that is a derivation for another post) and thats the blue one, not the red 😮!!!
Hence, lets think in terms of an ideal world. What would you expect as a perfect distribution for the error? Wouldn’t it be great if the model produced a delta function at zero as error distribution? It would mean that ALL the errors are zero with 100% chance! Of course you can’t produce that because the data is already there, and it has some finite “spread”. If you are a careful reader, you might have noticed that I’m avoiding to use the word “variance” like in “data with less variance”. Thats because a distribution can be “spread” in different ways. When we say “variance”, we, in general, mean the statistical measure. But that does not mean that the data is not “concentrated”. It might be concentrated in only two points. Two deltas separated by, say 10.0 units in the error axis, have a large variance (statistically speaking) but the data is very concentrated in the those two points.
So, what would be a good measure for this “concentrationness” or “spreadness” of the data in each model? The answer is: Entropy!
In the plots of figure 3, the red is the one that presents less entropy. So, problem solved right? Instead of measure the mean square of the error, we measure entropy of the error and we’re good. Well, almost… Yes, if we measure the entropy and minimize it, we have the distributions for the errors as close to a delta as the data allows. The problem is that the green model has the same entropy as the red one 😔… Unfortunately, mathematically speaking, we can’t avoid this problem. Entropy is insensitive to changes in the mean of the data, or insensitive to bias. But fortunately, that’s pretty much the only fundamental problem with entropy! So, in principle, you can minimize the entropy and them add a bias term (a constant to your model) to make it precise. This is not difficult to do. For instance, in our regression example, you minimize the entropy and get the green model (or any displaced model  ). You pass the data through this “trained” model and compute the mean of the output and call it
). You pass the data through this “trained” model and compute the mean of the output and call it  . Now you compute the mean of the original output and call it
. Now you compute the mean of the original output and call it  . Your final model will be
. Your final model will be  . That’s it.
. That’s it.
Well, problem solved! Right? Well, almost…
Now the problem is: how the heck do we compute the entropy of a set of points? The most known formula to compute entropy is the famous Shannon Entropy, given by
![\[ H(X) = -\int\limits_{ - \infty }^\infty {{f_X}(x)\log \left( {{f_X}(x)} \right)dx} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-5a8c71aa99783857418a360e15788329_l3.png "Rendered by QuickLaTeX.com")
or, if the variable is discrete, we have
![\[ H(X) = -\sum\limits_{i = 0}^{N} {{p_X}({x_i})\log \left( {{p_X}({x_i})} \right)} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-32517323705f5e8d0311469958a3f6d0_l3.png "Rendered by QuickLaTeX.com")
In both cases, the limits of integration and summation must be in accordance to the problem. For instance, if you have two variables, you have a double summation, integration, etc. The big problem is that, either case, we do not have the probability density ( ) or distribution (
) or distribution ( ).
).
To solve this problem we turn to estimators. The simplest of those estimators is the histogram. The histogram have a major drawback for us. Remember that the errors depend on the parameters of the model , therefore, the entropy, in our case, is an algebraic expression. To compute the histogram, we need the numerical values of the errors. But remember that we have numerical values only for the data, not for the errors. The errors depend on the parameters of the model which is exactly what we want to minimize over. So, we can’t differentiate the histogram with respect to to minimize it. Besides, the histogram does not even have an analytical expression to be differentiated in general.
The solution then is to use an analytical estimator, like Parzen windows. In short, the Parzen estimator for the density of a random variable, give some realizations of it, is given by
![\[ {f_X}(x) = \frac{1}{N}\sum\limits_{i = 0}^N {{k_\sigma }(x - {x_i})} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-d67e5f6e1dd333b9f1b5c1536d3b0da4_l3.png "Rendered by QuickLaTeX.com")
The fundamental item here is the kernel used in the estimatimative ( ). It is simply a “mini” probability distribution with “width”
). It is simply a “mini” probability distribution with “width”  . Without going into details, the most commonly used kernel is a gaussian with variance
. Without going into details, the most commonly used kernel is a gaussian with variance 
![\[ {k_\sigma }(x) = {G_\sigma }(x) = \frac{1}{{\sqrt {2\pi } \sigma }}{e^{ - \frac{{{x^2}}}{{2{\sigma ^2}}}}} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-ca22c130045c90aaebadd6c806023614_l3.png "Rendered by QuickLaTeX.com")
Hence, in our case, the samples of the error are give by (notice that each one depend on )
![\[ {e_i} = {y_i} - f({x_i},{\bf{w}}) \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-df4a8804ed433d50b84bee4a216dc865_l3.png "Rendered by QuickLaTeX.com")
and the density for the error random variable is (notice also that, since depend on ), the final density also depend on )
![\[ {f_E}(e) = \frac{1}{N}\sum\limits_{i = 0}^N {{G_\sigma }(e - {e_i})} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-fef448e8413fcf29dd516fc491cbd21b_l3.png "Rendered by QuickLaTeX.com")
Good, so we plug this expression in the formula for the entropy, integrate, differentiate with respect to and voilà! We have our algorithm (gradient, fix point, etc). Right? Not so fast…
Just for didactical purpose, let me write how would the the final entropy expression look like. Using the Shannon entropy and the Parzen window estimator for the density we have
![\[ H(E;{\bf{W}}) = \int\limits_{ - \infty }^\infty {\frac{1}{N}\sum\limits_{i = 0}^N {{G_\sigma }\left( {e - {e_i}} \right)} \log \left( {\frac{1}{N}\sum\limits_{i = 0}^N {{G_\sigma }\left( {e - {e_i}} \right)} } \right)de} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-517fd8177b9e353901e00dbf284ede42_l3.png "Rendered by QuickLaTeX.com")
The problem is that this integral in  is impossible to solve 😫! Logarithm of the sum of exponentials have no property to help the solution. They are nasty little math monsters!
is impossible to solve 😫! Logarithm of the sum of exponentials have no property to help the solution. They are nasty little math monsters!
Well, now we do the next big trick! Lets recapitulate why we wanted to use entropy. We want to use entropy because it has this nice property that it minimizes when the distributions are very narrow. But Shannon is one of the measures that have this property. There are lots of other options. In particular, we have Renyi’s entropy, given by
![\[ {H_\alpha }(X) = \frac{1}{{1 - \alpha }}\log \left( {\int\limits_{ - \infty }^\infty {f_X^\alpha (x)dx} } \right) \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-4804aeb611a1e43aef5ee7ac3e93cabb_l3.png "Rendered by QuickLaTeX.com")
This entropy have the same properties for all  . In particular, if we put
. In particular, if we put  (why not 1?) we have (for the error entropy)
(why not 1?) we have (for the error entropy)
![\[ {H_2}(E;{\bf{w}}) = - \log \left( {\int\limits_{ - \infty }^\infty {{{\left( {\frac{1}{N}\sum\limits_{i = 0}^N {{G_\sigma }\left( {e - e_i} \right)} } \right)}^2}dx} } \right) \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-1ae16d12c7237b1c51f7eccd62e095be_l3.png "Rendered by QuickLaTeX.com")
Now we can solve the integral (I will let this as an exercise to you) an get
![\[ {H_2}(E;{\bf{w}}) = - \log \left( {\frac{1}{{{N^2}}}\sum\limits_{i = 0}^N {\sum\limits_{j = 0}^N {{G_{\sqrt{2}\sigma} }\left( {{e_i} - {e_j}} \right)} } } \right) \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-4a41c62e2f8c36d4fdcd73290d79381c_l3.png "Rendered by QuickLaTeX.com")
Ok, now we have to stop a bit to contemplate the awesomeness of this expression… Most people do not realize how important and marvelous it is. It computes an estimative of the entropy of a random variable, given samples of it! Moreover, the samples can be given algebraically (remember that each depend on ). Now we can estimate the entropy just like we can estimate the mean or variance of a random variable by doing things like  (by the way, why do we compute the mean like that? Thats another post).
(by the way, why do we compute the mean like that? Thats another post).
Now finally we can differentiate  with respect to
with respect to  and we have as many entropy based algorithms as we wish!
and we have as many entropy based algorithms as we wish!
Information Potencial
As we saw in the previous section, we have an estimator for the entropy of the model given some measurement data. Going back to our simple regression example, we can find the and that minimizes the entropy by differentiating  with respect to and and follow the gradient (for instance).
with respect to and and follow the gradient (for instance).
Notice that we are not interested whatsoever in the value of the minimum entropy. We only want to know the values of and that minimizes it. Hence, we can get rid of that nasty logarithm and, instead of minimizing the entropy, we maximize its argument, given by
![\[ IP(E, \mathbf{w}) = {\frac{1}{{{N^2}}}\sum\limits_{i = 0}^N {\sum\limits_{j = 0}^N {{G_{\sqrt{2}\sigma} }\left( {{e_i} - {e_j}} \right)} } } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-296ab439ad183752f2fc9f679acc1731_l3.png "Rendered by QuickLaTeX.com")
This argument receives a special name: Information Potential. The origin of this name is interesting. Entropy is related to the information content of a random variable. If the variable is not very random, its entropy is low. In the case of the estimator we derived, the argument indicates the potential for the variable to be more or less random (depending on the values of the samples ). Actually, there is one algorithm that involves moving the samples in the direction of the derivative of the  , effectively generating information forces. But that’s another post…
, effectively generating information forces. But that’s another post…
In fact, the information potential is one of the cost functions  for ITL. So, instead of averaging the square of the error, we average all the pairwise combinations weighted by a gaussian (or the resulted function after integrating the kernel used in the density estimative).
for ITL. So, instead of averaging the square of the error, we average all the pairwise combinations weighted by a gaussian (or the resulted function after integrating the kernel used in the density estimative).
As an example, lets see what happens when we try to use the information potential in our simple regression problem. We plug the expression for the errors using our simple model and get the following
![\[ \begin{array}{l} J(\mathbf{w}) = \frac{1}{{{N^2}}}\sum\limits_{i = 0}^N {\sum\limits_{j = 0}^N {{G_{\sqrt{2}\sigma} }\left( {{y_i} - a{x_i} - b - {y_j} + a{x_j} + b} \right)} } \\ = \frac{1}{{{N^2}}}\sum\limits_{i = 0}^N {\sum\limits_{j = 0}^N {{G_{\sqrt{2}\sigma} }\left( {{y_i} - a{x_i} - {y_j} + a{x_j}} \right)} } \end{array} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-e290d1ad80381ce445f29ad75f3abb08_l3.png "Rendered by QuickLaTeX.com")
As you can see, the entropy (now our cost function) is independent of the term . As we explained in the beginning, any shift in the error by a constant would just shift its probability density by the same constant, leaving the entropy unaltered. Because of that, we have to do the trick of biasing the model (which is simple). If we differentiate this expression with respect to and maximize it (using gradient descent or something like that) we would get a better estimate then using MSE. That solution corresponds to finding models like the red and green on figure 3 and 1.
We now have the means to use entropy to train models. However, lets analyze two fundamental aspects of this estimator.
Computational cost
As we can see in the expression of the information potential, we have a double sum. Although it is a symmetric computation, which means that we actually just need to compute half of the terms, the algorithm is still  in complexity. Since the sums involve gaussians, there is a clever trick to compute it using gaussian transforms. Basically we use the fact that, when the argument of the gaussian is large, we can ignore it. In summary, the double sum is an issue that must be addressed when using entropy to train a model.
in complexity. Since the sums involve gaussians, there is a clever trick to compute it using gaussian transforms. Basically we use the fact that, when the argument of the gaussian is large, we can ignore it. In summary, the double sum is an issue that must be addressed when using entropy to train a model.
Kernel size
The kernel size is the most important aspect of ITL. When we derived the entropy estimator, there was an important piece of information that was overlooked. It was the width of the kernels used in the estimator. We call it the kernel size. In his paper, Parzen showed that, in order for us to have a good estimation of the pdf of the data, the size of the kernel must decrease to zero as the number of points tends do infinity. The exact way this decreasing must occur depend on the data itself. There are some “rules” that tries to estimate this relationship ( versus  ) but in the ITL case, this it is very difficult because, for each model parameter , we have a different distribution. So, in theory, we should have an estimative for that is dependent. However, remember that we do not want the value of the entropy or information potential themselves. We rather want the that maximizes it. In practice, we do tests with different values of kernel sizes and, in general, its not too difficult to find a suitable one. In the end, even if the estimative of the entropy is not perfect, the gain of having some estimative surpasses by far the disadvantages of not being precise in the measure.
) but in the ITL case, this it is very difficult because, for each model parameter , we have a different distribution. So, in theory, we should have an estimative for that is dependent. However, remember that we do not want the value of the entropy or information potential themselves. We rather want the that maximizes it. In practice, we do tests with different values of kernel sizes and, in general, its not too difficult to find a suitable one. In the end, even if the estimative of the entropy is not perfect, the gain of having some estimative surpasses by far the disadvantages of not being precise in the measure.
Demo
Bellow you can find a little demo for the concept of Information Potential. The first plot is the plot for the regression. You can see the data and two models. The gray model is the correct model. It is the true phenomenon that relates to . The data, as you can see, do not fit perfectly on the model due to noise. The second model you can set by changing the sliders “a” and “b”. The plot bellow is the density function of the error for the model. You can set the kernel size for the estimative of the distribution on the third slider. Between the plots we can see the MSE and Entropy measurement for blue model.
You can play with the sliders and see how things change. In particular, try to find the positions where you have minimum MSE e/or minimum entropy. Compare the values for and in both cases. From the true model, try to compute the correct values (another exercise for you).
Correntropy
When we look at the information potential expression, we realize that it looks like some sort of estimation of a expected value of something. In fact, if were a stochastic process, we might imagined that there is some measure between the different lags in the process and we were taking the average of that measure.
That leads us to think that there exists this measure, that we are going to call “Correntropy”, that measures some sort of statistical relationship between two random variables. In fact, the Information Potential is the expected value of this quantity when the two random variables are samples with different lags in some stochastic process. Since the information potential came from Renyi’s Entropy, and now we are measuring some sort or “correlation” between two random variables, the name Correntropy seems adequate. Hence, initially, Correntropy will be estimated like so
![\[ \tilde V(X,Y) = \frac{1}{N}\sum\limits_{i = 1}^N {{k_\sigma }({x_i} - {y_i})} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-7400ee2ca526191c94c45256d35689ab_l3.png "Rendered by QuickLaTeX.com")
and defined as
![\[ V(X,Y) = E\left\{ {{k_\sigma }(X, Y)} \right\} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-4baf87d1141c487e9d59c24ace318984_l3.png "Rendered by QuickLaTeX.com")
Notice that the kernel used here do not need to be the gaussian kernel. It came originally from the Parzen estimation of the error probability in the IP. This will be important in a later section. Also, notice the difference in notation. The second expression depend on the random variables directly, while the first depend on its samples (random variables are non-bold uppercase and values are lowercase).
Now we have this weird but simple-looking expression that apparently measures some sort of “correlation” between variables  and
and  . In fact, as we are going to see, this measure is far more powerful than a simple correlation. It is, in fact, related to high order statistics and inner products in a larger Hilbert Space.
. In fact, as we are going to see, this measure is far more powerful than a simple correlation. It is, in fact, related to high order statistics and inner products in a larger Hilbert Space.
Before diving into the deeper analysis of this measure, let first point out some important facts. First, we have a bivariate measure. It means that we are measuring some sort of relationship between two sets of samples (realizations of random variables). As opposed to the IP, now we need two random variables to plug into the measure. Second, we jumped from an estimation to a definition of a measure. For theoretical purposes, we can (and will) use the definition of Correntropy, instead of its estimation, to draw important conclusions about its statistical and analytical behavior. Lastly, by construction, Correntropy depends on a kernel and a kernel size. That is important because we frequently see papers claiming that they “generalized” Correntropy when, in fact, they exchanged the Gaussian kernel for some other kernel and obtained some more general result.
In the next three sections, we will try to gain some theoretical insight about Correntropy. First we will “dissect” it and show that it corresponds to a generalized statistical measure. Then, we will present two fundamental “interpretations” for Correntopy that leads to two different understandings of it. There is no “correct” interpretation. We simply have different ways of interpreting what the expression can mean.
Generalized statistics
Here we will “dissect” the expression for Correntropy. The tool we will use for that is the Taylor series expansion. Hence, without further ado, here goes the Taylor expansion for Correntropy using the Gaussian kernel around  (yet another exercise for you).
(yet another exercise for you).
![\[ V(X,Y) = \frac{1}{{\sqrt {2\pi } \sigma }}E\left\{ {\sum\limits_{i = 0}^\infty {\frac{{{{\left( { - 1} \right)}^i}\,{{(X - Y)}^{2i}}}}{{i!{2^i}{\sigma ^{2i}}}}} } \right\} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-4e9a71c72086ff9bdc33d4190c005032_l3.png "Rendered by QuickLaTeX.com")
There is something very interesting hidden in this expansion. To see what it is, lets look at the first terms in this series (pulling aways the constant factors for each one for simplicity’s sake)
![\[ \begin{gathered} V(X,Y) = {c_1}E\left\{ {\,{{(X - Y)}^2}} \right\} + {c_2}E\left\{ {\,{{(X - Y)}^4}} \right\} + … \hfill \\ = {c_1}E\left\{ {\,{X^2}} \right\} + {c_1}E\left\{ {\,{Y^2}} \right\} + 2{c_1}E\left\{ {\,XY} \right\} + {c_2}E\left\{ {\,{X^4}} \right\} + {c_2}E\left\{ {{Y^4}} \right\} + … \hfill \\ \end{gathered} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-65f26880e7ca94f32f2c806afda081fe_l3.png "Rendered by QuickLaTeX.com")
Since we can always “whiten” our data making all first single variable constant ( ,
,  ,
,  and etc), we can rewrite the Correntropy as something like:
and etc), we can rewrite the Correntropy as something like:
![\[ V(X,Y) = {c_0} + \frac{{{c_1}}}{{{\sigma ^3}}}E\left\{ {\,XY} \right\} + \frac{{{c_1}}}{{{\sigma ^6}}}E\left\{ {X{Y^3}} \right\} + \frac{{{c_1}}}{{{\sigma ^6}}}E\left\{ {{X^2}{Y^2}} \right\} + … \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-ef67d718bd51b8221856b8a1a0774118_l3.png "Rendered by QuickLaTeX.com")
We can now see that Correntropy is a generalized correlation measure that takes into account all the even statistical moments of the variables X and Y. Moreover, if we increase the kernel size , higher order terms vanishes “more quickly” than the lower ones. Hence, if we make the kernel size high enough we can make Correntropy behave like a simple second order correlation. Well, there is a little technical drawback on this last “property” of Correntropy. As it turned out, the constant  sitting there in the expansion is proportional to
sitting there in the expansion is proportional to  , so if we increase the kernel size too much, we get a constant function, not the simple correlation function between X and Y. But that is a technical issue, since we can aways remove some value to whatever we are measuring with Correntropy.
, so if we increase the kernel size too much, we get a constant function, not the simple correlation function between X and Y. But that is a technical issue, since we can aways remove some value to whatever we are measuring with Correntropy.
Now we can use Correntropy as a generalized correlation function. Any statistical method that uses correlation now can have a Correntropy version. Just like we exchanged Mean Square Error by entropy in the previous sections, we can now exchange correlation to Correntropy.
RKHS Interpretation
When dealing with a stochastic process or stochastic function  (or
(or ![X[m]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-34f8a32e15370f0d419d67e3d4eeda2d_l3.png "Rendered by QuickLaTeX.com") in the discrete case), it is very common to refer as its covariance “kernel”
in the discrete case), it is very common to refer as its covariance “kernel”
![\[ R(s,t) = E\left\{ X(s)X(t) \right\} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-488ff831fb4254f253fff8f9b9049ed1_l3.png "Rendered by QuickLaTeX.com")
This is an important function that turns out to describe a lot about the process itself. However, this is the case when the process has second order nature. In another words, when the process is mainly described by the covariance between the “taps” at  and
and  . Unfortunately this is not always the case.
. Unfortunately this is not always the case.
Nevertheless, Parzen (him again) showed in a brilliant paper that a stochastic process give rise to an abstract Hilbert Space (technically a Reproducing Kernel Hilbert Space, or RKHS in short). Basically, for a given stochastic process , there exists a RKHS  in which random variables can be viewed as vectors in this abstract space. Hence, everything you can do with random variables, we can now have an equivalent operation as vectors. For instance, inner products with random variables in one space, means correlation in the other. We can also measure the “square length” of a variable and that means variance. And so on.
in which random variables can be viewed as vectors in this abstract space. Hence, everything you can do with random variables, we can now have an equivalent operation as vectors. For instance, inner products with random variables in one space, means correlation in the other. We can also measure the “square length” of a variable and that means variance. And so on.
In essence, Parzen’s paper tremendous contribution wasn’t to provide new tools to deal with random variables. Instead, he gave us a very powerful interpretation of random variables as vectors in this abstract RKHS spanned by a stochastic process.
But wait… We must remember that RKHS is a big trend in the past years as the “kernel methods” for machine learning arose. In particular, the theorems due to Moore-Aronszajain and Mercer that shows that, when you evaluate the kernel in the “original” space, you are performing a inner product in the “feature” space that have a bigger (even infinite) dimension. Then, due to another big theorem, we know that when we project things from a lower dimension to a higher dimension, the projected vectors tend to be linearly related to each other.
Even better, in order for this to be true, you just need the kernel to be a positive definite function. Because of that, we can do all kinds of crazy projections using non-linear functions as kernel and we would be, in fact, doing linear algebra in some crazy abstract space. That is the famous “kernel trick” (that is a subject for another post).
Now we call “probability space” as “original space” and “Hilbert Space” as “feature space” and voila! We now have kernel methods for random variables!!! But what the heck does any of this have to do with Correntropy? Well… Remember the definition of Correntopy as the expected value of a function of the two random variables? It so happens that if that function is positive definite (as the Gaussian kernel is, for instance) we have exactly the same “kernel trick” in statistics that we have in machine learning!!!
In essence, when we compute Correntropy, we are computing the inner product in some RKHS spanned by some random process that have and as vectors transformed by a crazy function, like
![\[ V(X,Y) = E\left\{ {{k_\sigma }(X,Y)} \right\} = \left\langle {\Phi (X),\Phi (Y)} \right\rangle = E\left\{ {f(X)f(Y)} \right\} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-3c2638f5c0a12a24df5e9591644a9b1a_l3.png "Rendered by QuickLaTeX.com")
So, in summary, Correntropy can be viewed as a mean to compute a linear inner product in some space in which the transformation from the original space is non linear. In another world, we can perform the kernel trick for random variables!
Example
As an example, lets consider a case of non-linear regression with Correntropy. The idea is to use the “Correntropy kernel trick” to go from a linear regression to its non-linear version. So, lets start with the linear formulation. We have the following relationship
![\[ y = {\mathbf{w}^t}{\mathbf{x}} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-52c13b7cdbcf75b85efbad41d112c9fa_l3.png "Rendered by QuickLaTeX.com")
We will suppose that we have samples of and  and wish to find .
and wish to find .
The trick is to “kernalize” this problem, but still keep things linear (see the other post about the kernel trick). To do this, we will write as a linear combination of some “support” vectors  as
as
![\[ {\mathbf{w}^t} = \sum\limits_{l = 1}^L {{a_l}{\mathbf{c}}_l^t} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-8613a16314cf68b78f6614137bc5f841_l3.png "Rendered by QuickLaTeX.com")
Now, instead of trying to find , we will chose some vectors  (somewhat arbitrarily) and try to find
(somewhat arbitrarily) and try to find  .
.
If we do this in the linear case, we might ask: What the heck??? You just exchanged 6 by half a dozen! And we would be right. But lets keep going and see where this is going.
We now have some measurements for as  and for as
and for as  . We then substitute the expression for and get
. We then substitute the expression for and get
![\[ \begin{gathered} {d_k} = \sum\limits_{l = 1}^L {{a_l}{\mathbf{c}}_l^t{\mathbf{x}}} \hfill \\ = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {{c_{i,l}}{x_{i,k}}} } \hfill \\ \end{gathered} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-afd3b88c04e34700bc4758d23fe70e9d_l3.png "Rendered by QuickLaTeX.com")
As all the measurements and choices of vectors are random variables, we choose the following notation
![\[ {D_k} = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {{C_{i,l}}{X_{i,k}}} } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-e5423a7a21328da6361212523533f28f_l3.png "Rendered by QuickLaTeX.com")
That is the relationship that should provide the pathway to our kernel trick. Lets take the expected value on both sides:
![\[ E\left\{ {{D_k}} \right\} = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {E\left\{ {{C_{i,l}}{X_{i,k}}} \right\}} } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-e6168de0eb6aa747b978cc689d898bcd_l3.png "Rendered by QuickLaTeX.com")
And there it is! Right there!  is our friend linear stochastic kernel. That means that this whole thing can be consider as a linear regression on a crazy RKHS that has a non-linear transform back to our original space. Since this expected value is a inner product on this RKHS, we can translate it to our original space via Correntropy kernel trick
is our friend linear stochastic kernel. That means that this whole thing can be consider as a linear regression on a crazy RKHS that has a non-linear transform back to our original space. Since this expected value is a inner product on this RKHS, we can translate it to our original space via Correntropy kernel trick
![\[ E\left\{ {{D_k}} \right\} = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {V\left( {{C_{i,l}}{X_{i,k}}} \right)} } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-012214b87763902a338e30dcad585165_l3.png "Rendered by QuickLaTeX.com")
Now we can find the constants via
![\[ {\mathbf{a}} = {{\mathbf{M}}^\bot }{\mathbf{p}} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-29a9f14e628432878abb3183ff44cdad_l3.png "Rendered by QuickLaTeX.com")
Where the little cross on  means pseudo inverse and the variables are defined as
means pseudo inverse and the variables are defined as
![\[ \begin{gathered} {\mathbf{M}} = \left[ {\begin{array}{*{20}{c}} {V\left( {{C_{1,1}}{X_{1,1}}} \right) + … + V\left( {{C_{d,1}}{X_{d,1}}} \right)}& \cdots &{V\left( {{C_{1,L}}{X_{1,1}}} \right) + … + V\left( {{C_{d,L}}{X_{d,1}}} \right)} \\ \vdots & \ddots & \vdots \\ {V\left( {{C_{1,1}}{X_{1,K}}} \right) + … + V\left( {{C_{d,1}}{X_{d,K}}} \right)}& \cdots &{V\left( {{C_{1,L}}{X_{1,K}}} \right) + … + V\left( {{C_{d,L}}{X_{d,K}}} \right)} \end{array}} \right] \hfill \\ {\mathbf{p}} = \left[ {\begin{array}{*{20}{c}} {E\left\{ {{D_1}} \right\}} \\ \vdots \\ {E\left\{ {{D_K}} \right\}} \end{array}} \right] \hfill \\ \end{gathered} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-f20214d1fcb5e1906bc366b0e04248bd_l3.png "Rendered by QuickLaTeX.com")
One important aspect of this solution is that we have  random variables for each problem variable (,
random variables for each problem variable (,  and
and  ). This means that we should “repeat” the measurements times in order to obtain enough statistics to be able to compute Correntropy for each variable. That is not a problem because we can always divide our data into groups (separated independently) and use the groups as repeated measurements.
). This means that we should “repeat” the measurements times in order to obtain enough statistics to be able to compute Correntropy for each variable. That is not a problem because we can always divide our data into groups (separated independently) and use the groups as repeated measurements.
Now we have the relationship that computes in the original space
![\[ y = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {V\left( {{C_{i,l}}{X_i}} \right)} } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-cd7503f5227956bb869bca71c887f579_l3.png "Rendered by QuickLaTeX.com")
In general, we can choose the support vectors as we want, so we pick them as random variables with delta distribution over some constants . Also, the point is an a posteriori measurement, so we know its value and can consider it as a random variable with a delta distribution. If that is the case, the expected value of the kernel, is the kernel itself. Hence, we have our non-linear model as
![\[ y = \sum\limits_{l = 1}^L {{a_l}\sum\limits_i^d {{k_\sigma }\left( {{c_{i,l}}{x_i}} \right)} } \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-726ee803f09b7d90b2e85015b23850b8_l3.png "Rendered by QuickLaTeX.com")
Probability Interpretation
Correntropy hides another super interesting interpretation. This time lets show this “property” of Correntropy by going backwards. Lets first state the property and then arrive at the definition of Correntropy. It turns out that Correntopy is actually the probability density of the event  when the kernel size tends to zero. So, in essence, when we estimate Correntropy between two variables (we say estimate because remember that the definition involves an expected value and in practice the kernel size is never zero) we are estimating the probability that both variables are equal. Moreover, this estimation is numerically the same as the estimation using the Parzen windows method for estimating the density of the joint distribution of and .
when the kernel size tends to zero. So, in essence, when we estimate Correntropy between two variables (we say estimate because remember that the definition involves an expected value and in practice the kernel size is never zero) we are estimating the probability that both variables are equal. Moreover, this estimation is numerically the same as the estimation using the Parzen windows method for estimating the density of the joint distribution of and .
So, lets start by estimating the density of the joint space by
![\[ {f_{XY}}\left( {X,Y} \right) = \frac{1}{N}\sum\limits_{i = 1}^N {{k_\sigma }\left( {x - {x_i},y - {y_i}} \right)} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-578cea6ffc9b0814b1eac42c78fd21bb_l3.png "Rendered by QuickLaTeX.com")
Notice that the joint space is bi-dimensional  . Because of that, the kernel must also be a bi-dimensional entity. For the sake of simplicity, we will see how this works with a gaussian kernel, but the concept is more general. The gaussian kernel, then, is defined as
. Because of that, the kernel must also be a bi-dimensional entity. For the sake of simplicity, we will see how this works with a gaussian kernel, but the concept is more general. The gaussian kernel, then, is defined as
![\[ {k_\sigma }\left( {x,y} \right) = \frac{1}{{2\pi {\sigma ^2}}}{e^{ - \frac{{{x^2} + {y^2}}}{{2{\sigma ^2}}}}} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-0587b1f50f6dc85be54b9cc6da29de44_l3.png "Rendered by QuickLaTeX.com")
Now we can compute the probability of the event . To do that, we should integrate the joint density along the curve that defines the event. In the case of , it is very simple and we just need to integrate along the 45 degree line with a delta function. This is achieved by the integral
![\[ \begin{array}{l} P(X = Y) = \int\limits_{ - \infty }^\infty {\int\limits_{ - \infty }^\infty {{f_{XY}}\left( {x,y} \right)\delta (x - y){\rm{d}}x{\rm{d}}y} } \\ = \int\limits_{ - \infty }^\infty {{f_{XY}}\left( {u,u} \right){\rm{d}}u} \end{array} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-6dcf9dd83004969ff256f863c6dd3539_l3.png "Rendered by QuickLaTeX.com")
Using the Parzen estimative for the density we have
![\[ \begin{array}{l} P(X = Y) = \frac{1}{N}\sum\limits_{i = 1}^N {\int\limits_{ - \infty }^\infty {{k_\sigma }\left( {u - {x_i},u - {y_i}} \right){\rm{d}}u} } \\ = \frac{1}{N}\sum\limits_{i = 1}^N {\int\limits_{ - \infty }^\infty {\frac{1}{{2\pi {\sigma ^2}}}{e^{ - \frac{{{{(u - {x_i})}^2} + {{(u - {y_i})}^2}}}{{2{\sigma ^2}}}}}{\rm{d}}u} } \end{array} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-8dbc49b9327a5a67e189248a4ce69faf_l3.png "Rendered by QuickLaTeX.com")
If we solve the integral, we can write the expression for the probability as
![\[ P(X = Y) = \frac{1}{N}\sum\limits_{i = 1}^N {{G_{\sqrt 2 \sigma }}\left( {{x_i} - {y_i}} \right)} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-7cac565956ac4fa8935a9c57db30de5a_l3.png "Rendered by QuickLaTeX.com")
Which is exactly the estimative for Correntropy when we use the approximation for the expected value!
Example
We can use this Interpretation of Correntopy as a cost function. In fact, as a cost function, it is extremely intuitive because if you have a measured random variable and a parametrized model, the cost function will be probability that the model is equal to the measurement! Hence, you simple maximize this quantity and you’re done. As a simple example, lets consider a polynomial regression. Our model now will be
![\[ y = a{x^2} + bx + c \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-181ebefee59ec301085e073c21c2501a_l3.png "Rendered by QuickLaTeX.com")
We have some measurements of the pair  and, with that, we can compute the estimative of
and, with that, we can compute the estimative of  . Now we have the two random variables and
. Now we have the two random variables and  . Finally, we just need to maximize the probability of the event
. Finally, we just need to maximize the probability of the event  . In another words, our cost function (cost here is a mislead word) will be
. In another words, our cost function (cost here is a mislead word) will be  as
as
![\[ P(Y = \hat Y|a,b,c) = \frac{1}{N}\sum\limits_{i = 1}^N {{G_{\sqrt 2 \sigma }}\left( {ax_i^2 + b{x_i} + c - {y_i}} \right)} \]](https://www.dev-mind.blog/wp-content/ql-cache/quicklatex.com-fe2429f94d88f7a82cf3e30dd9d103c5_l3.png "Rendered by QuickLaTeX.com")
As you can see, unlike the entropy in the previous sections, Correntropy have no bias problem (if you change the bias term, the Correntropy does not remains constant) and its estimator have only one summation. The outlier rejection property is still present. One can notice that points that are too far form the model, will be expressed as a large value in the argument of the kernel. That makes it have very little impact on the overall cost function value.
Demo
In this demo we try to illustrate the probability interpretation of Correntropy. It shows the polynomial regression described in the previous section. The sliders controls the value of the parameters of the parabola  and the kernel size. The first plot shows the measurements , the correct model and chosen model. As you change the sliders, you can see the fitting parabola change as well as the samples in the space
and the kernel size. The first plot shows the measurements , the correct model and chosen model. As you change the sliders, you can see the fitting parabola change as well as the samples in the space  in the plot bellow. The third plot shows the probability density estimation for the joint space and a plane that cuts the probability at the line . The idea is that, when you fit the right parabola, the area of the joint density will be maximum in the plane
in the plot bellow. The third plot shows the probability density estimation for the joint space and a plane that cuts the probability at the line . The idea is that, when you fit the right parabola, the area of the joint density will be maximum in the plane
Conclusions
Information Theoretic Learning is a great framework for machine learning. It has a lot more to it then we presented here. The goal is to introduce the reader to this new and awesome concept. Since it deals with entropy, things like mutual information, Cauchy–Schwarz relations, and etc, can be used in the process of learning. Even non-parametric algorithms can benefit from ITL. Because of that, not only it is a new way to define cost functions, but rather it is an unifying framework for learning in general! Depending how you use the metrics, one can have supervised and non-supervised algorithms, fitting of non-linear and linear models, generalized statistics among others.
I hope that in future posts we can talk more about this impressive framework! I hope you liked to learn a bit about it, and see you in the next post!
References
[1] – Principe, Jose C., Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives, Springer
[2] – Denis Erdogmus, INFORMATION THEORETIC LEARNING: RENYI’S ENTROPY AND ITS APPLICATIONS TO ADAPTIVE SYSTEM TRAINING
[3] – Weifeng Liu ; Puskal P. Pokharel ; Jose C. Principe, Correntropy: Properties and Applications in Non-Gaussian Signal Processing, IEEE Transactions on Signal Processing, Volume: 55, Issue: 11, Nov. 2007
[4] – Jian-Wu Xu, Student Member, IEEE, António R. C. Paiva, Student Member, IEEE, Il Park (Memming), and Jose C. Principe, Fellow, IEEE, A Reproducing Kernel Hilbert Space Framework for Information-Theoretic Learning, IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 56, NO. 12, DECEMBER 2008 5891
[5] – E. Parzen, On Estimation of a Probability Density Function and Mode, Ann. Math. Statist., Volume 33, Number 3 (1962), 1065-1076.
[6] – E. Parzen, Statistical Inference on Time Series by Hilbert Space Methods, I.
Office of Naval Research Report Number CHEONR23, Jan 1959